Erste Schritte mit Open WebUI
Diese Kurzanleitung bietet einen schnellen Überblick über die wichtigsten Funktionen der Oberfläche.
Sie richtet sich an Nutzer*innen, die Open WebUI erstmals verwenden. Eine ausführlichere Anleitung steht separat zur Verfügung.
Open WebUI ist eine webbasierte Oberfläche zur Interaktion mit generativen Sprachmodellen, in der Eingaben als Chat erfolgen und Antworten direkt angezeigt werden.
1. Orientierung
Nach dem Öffnen gliedert sich die Anwendung in mehrere Bereiche:
- Obere Leiste: Auswahl des Modells sowie Zugriff auf Workspaces und Einstellungen
- Seitenleiste: Gesprächsverlauf, Ordner, Tags und Workspaces
- Hauptbereich: Aktiver Chat
- Eingabefeld: Texteingabe, Datei-Upload und Senden der Anfrage

2. Einen Chat starten
- Auf „Neuer Chat“ klicken
- Ggf. ein Modell auswählen. Modelle können per Namen gesucht oder über die Kategorie-Reiter gefiltert werden.
- Nachricht eintippen. Enter zum Senden. Shift+Enter für einen Zeilenumbruch ohne Absenden. Dateien können auch per Drag & Drop direkt in den Eingabebereich gezogen werden.
- Mit Enter senden
Antworten erscheinen direkt im Chat und bauen auf dem bisherigen Verlauf auf.
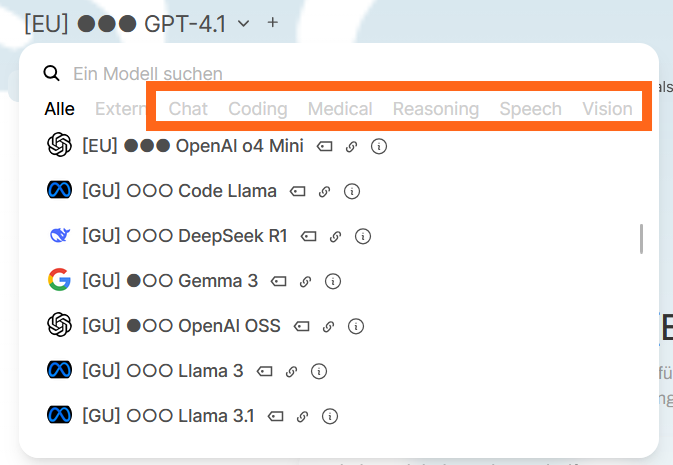
Modell-Praefixe – Hosting und Datensicherheit
Jeder Modellname in dieser Instanz enthalt ein Prafix, das den Hosting-Standort und die Datenverarbeitung anzeigt. Dies ist der wichtigste Faktor beim Umgang mit sensiblen oder personenbezogenen Daten:
| Präfix | Standort | Datenverarbeitung |
| [EU] | Azure Europa (EU-Rechenzentren) | Unterliegt den Microsoft-Datenverarbeitungsbedingungen. DSGVO-konformes EU-Hosting. |
| [DE] | GWDG Deutschland | Verarbeitung auf GWDG-Servern in Deutschland. |
| [GU] | Goethe-Universität lokal | Vollständige Verarbeitung auf GU-Infrastruktur. |
| ⚠️ Hinweis: Die drei Punkte neben dem Modellnamen geben Aufschluss über die Modellgröße (Anzahl der Parameter). – ○○○: < 10B, – ●○○: 10B – 80B – ●●○: 80B – 500B – ●●●: 500B+ und geschlossen GPT / o-series |
2.1 Mikrofon und Sprach-Anruf-Schaltflache
- Mikrofon (Sprache-zu-Text): Anklicken zum Aufzeichnen. Open WebUI transkribiert die Sprache in Text und platziert ihn im Eingabefeld. Benötigt Mikrofon-Berechtigung im Browser. Unterstutzt durch Whisper oder die browser-eigene Sprach-API.
- Sprach-Anruf-Modus: Startet ein Echtzeit-Gespräch mit der KI. Das Modell hört zu, transkribiert und antwortet mit synthetischer Sprache (Text-to-Speech). Optional kann die Kamera fur eine videobasierte Interaktion aktiviert werden.
Rechts neben dem Eingabefeld befinden sich zwei Audio-Steuerelemente:
2.2 Das „+“ Symbol: Anhänge
Ein Klick auf das „+“ Symbol im Eingabebereich öffnet ein Menü mit verschiedenen Optionen, um Nachrichten zu erweitern. Die verfügbaren Optionen hangen von der Konfiguration dieser Instanz und dem gewählten Modell ab:

- Dateien hochladen: Dokumente (PDF, Word, Excel, Textdateien), Bilder, Audiodateien und mehr anhängen. Die KI liest und analysiert den Inhalt als Teil des Gesprächs. Unterstutzte Formate: PDF, DOCX, TXT, CSV, XLSX, JPEG, PNG sowie MP3/WAV-Audiodateien.
- Aufnahme: Die Bildschirmfreigabe erfasst den aktuellen Bildschirminhalt. Visionsfähige Modelle (z. B. [EU] GPT-4o) konnen dann analysieren, was sie sehen.
- Webseite anHängen:
- Notizen anhängen:
- Wissen anhängen: das „#“ Symbol in das Nachrichtenfeld eingeben (oder hier auswählen), um eine Wissensdatenbank oder ein bereits hochgeladenes Dokument zu referenzieren. Die KI durchsucht es per RAG (Retrieval-Augmented Generation), um die Antwort auf den eigenen Materialien zu basieren.
2.2 Das Integrationen-Symbol: Funktionen aktivieren

- Websuche: Ermöglicht der KI, vor der Antwort in Echtzeit im Internet zu suchen. Diesen Schalter aktivieren, wenn aktuelle Informationen benötigt werden, die über das Trainingsdatum des Modells hinausgehen. Das Modell nennt seine Quellen. Bitte beachte, dass Webseiten, die eine Anmeldung, ein CAPTCHA oder ähnliche Schritte erfordern, für das Modell möglicherweise nicht zugänglich sind.
- Bildgenerierung: Dieser Schalter ermöglicht die Text-zu-Bild-Generierung direkt im Chat. Das gewünschte Bild beschreiben; das Modell erstellt es inline.
- Code-Interpreter: Ermöglicht dem Modell, Python-Code direkt im Gespräch zu schreiben und auszufuhren. Ergebnisse, Diagramme und berechnete Ausgaben erscheinen direkt unterhalb des Code-Blocks. Besonders nützlich für Datenanalyse, Berechnungen und Visualisierungen.
3. Chats organisieren Mit Ordnern
Mit Ordnern können Sie Chats in einem Bereich gruppieren und gleichzeitig spezifische Anweisungen (System-Prompts) für alle Chats in diesem Ordner festlegen.

Das Dialogfenster „Ordner erstellen“ enthält folgende Felder:
| Feld | Beschreibung |
|---|---|
| Ordnername | Einen aussagekräftigen Namen vergeben, z. B. „Seminar SoSe 2026″ oder „Forschungsprojekt KI“. |
| Ordner-Hintergrundbild | Optional ein Bild hochladen, das als visuelles Erkennungsmerkmal für den Ordner dient. |
| System-Prompt | Ein System-Prompt, der automatisch für alle Chats innerhalb dieses Ordners gilt. So kann z. B. für einen Seminar-Ordner festgelegt werden, dass die KI immer auf Deutsch antwortet und im APA-Format zitiert — ohne dass dies in jedem Chat neu eingegeben werden muss. |
| Wissen | Eine Wissensdatenbank aus dem Arbeitsbereich anhängen oder Dateien direkt hochladen. Diese Wissensquelle steht dann allen Chats im Ordner automatisch zur Verfügung. |
4. Mit Notizen arbeiten
Mit Notizen können Sie Ihre Notizen mit Unterstützung der Chatbots schreiben. Sie können einzeln oder gemeinsam mit dem Chatbot schreiben.
Notizen ist ein eigenständiger Rich-Text-Bereich, der unabhängig von einzelnen Chats existiert. Im Gegensatz zu einem Chat-Gespräch bleibt eine Notiz dauerhaft erhalten und kann an mehrere Chats als Kontext angehängt werden.
Typische Nutzung:
- Notizen über die linke Seitenleiste öffnen.
- Mit dem Rich-Text-Editor freischreiben (Überschriften, Listen, Fettdruck, Kursivschrift usw.).
- KI zur Hilfe nehmen: Text in der Notiz markieren und die KI bitten, ihn direkt zu überarbeiten, zu erweitern, zu korrigieren oder zu übersetzen.
- Notiz an einen Chat anhängen (über das +-Symbol im Eingabebereich), damit die KI den Inhalt als Kontext nutzen kann — der vollständige Inhalt wird stets eingespeist, ohne Chunking oder Vektorsuche.
- Notizen als persönliche Prompt-Bibliothek verwenden: Bewährte Prompts speichern und sitzungsübergreifend wiederverwenden.

5. Dokumente hochladen
Dokumente und andere Dateien können auf zwei Wegen an Nachrichten angehängt werden:
- Eine Datei per Drag & Drop vom Dateimanager direkt in den Eingabebereich ziehen.
- Das +-Symbol im Eingabebereich anklicken und „Dateien hochladen“ auswählen.
Der Text wird automatisch extrahiert und kann im Chat verwendet werden.
| Nach dem Hochladen eines Dokuments kann das Anhang-Badge angeklickt werden, um „Gesamtes Dokument verwenden“ auszuwählen. Im Standard-RAG-Modus ruft die KI nur die relevantesten Passagen ab, was schneller ist und weniger Kontext verbraucht. |
6. Arbeitsbereich: Überblick
Der Arbeitsbereich (Seitenleisten-Element) ist das erweiterte Konfigurationszentrum. Hier werden dauerhafte, wiederverwendbare KI-Setups aufgebaut. Die Hauptbereiche sind:
- Modelle: Benutzerdefinierte Modell-Presets (Agenten) erstellen mit spezifischem Basismodell, System-Prompt, angehangten Wissensdatenbanken und Tool-Einstellungen. Eigene Modelle erscheinen in der Modellauswahl.
- Wissen: Benannte Dokumentensammlungen anlegen. Die KI durchsucht diese Sammlungen per RAG, wenn Fragen auf Basis eigener Materialien beantwortet werden sollen.
- Prompts: Häufig verwendete Prompt-Texte als wiederverwendbare Vorlagen speichern. Vorlagen in einem Chat mit „/“ gefolgt vom Vorlagennamen aufrufen.
| Für den täglichen Einsatz ist keine Konfiguration im Arbeitsbereich erforderlich. Die verfügbaren Modelle in der Auswahl sind direkt nutzbar. Erkunden Sie den Arbeitsbereich, wenn Sie spezialisierte Assistenten oder dauerhafte Wissensdatenbanken erstellen möchten. Weitere Informationen zum Erstellen von Agenten und Wissen finden Sie im Advancd Guide. |