Allgemein
Was ist Whisper-WebUI und wofür kann es genutzt werden?
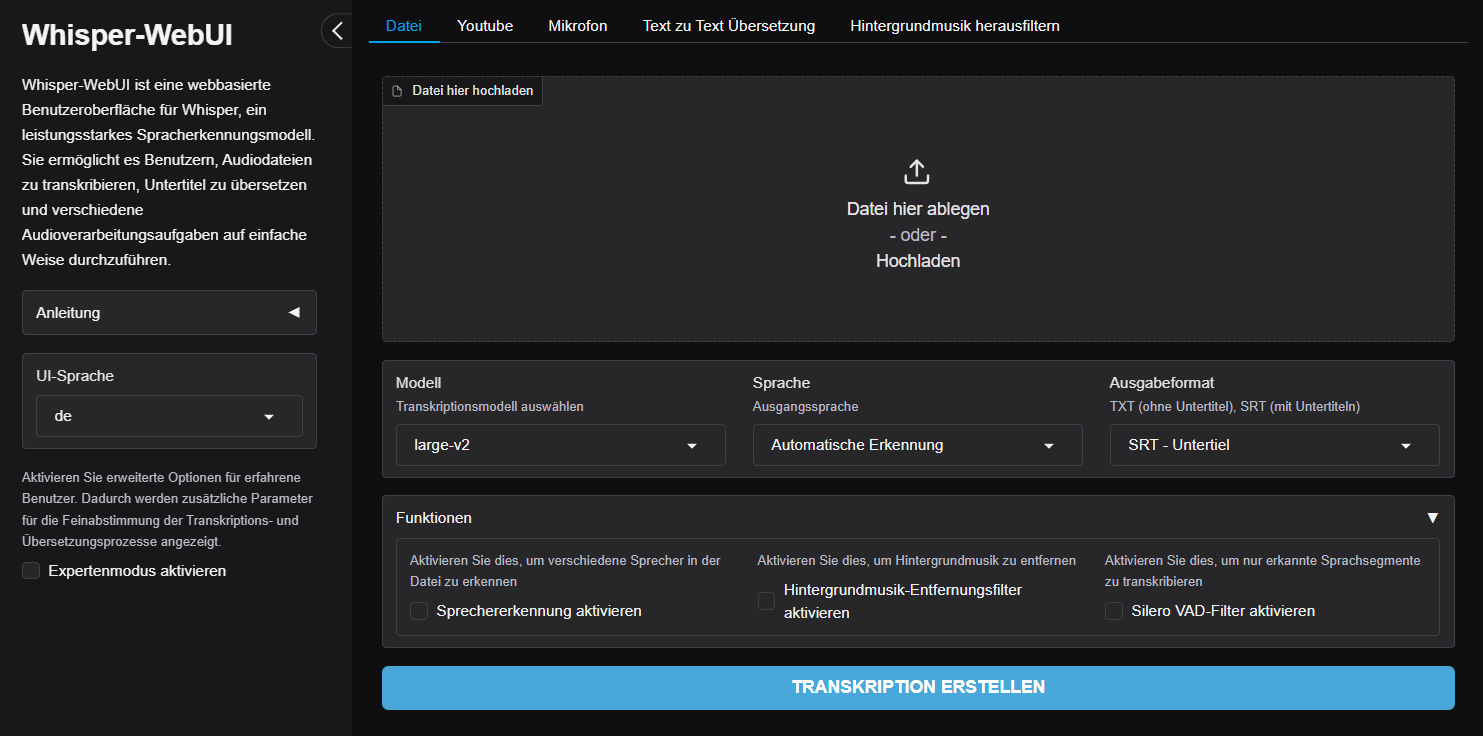
Whisper-WebUI ist eine browserbasierte Anwendung zur automatisierten Transkription und Untertitelung von Audio- und Videodateien. Mit seiner benutzerfreundlichen Oberfläche und der Integration des KI-gestützten Whisper-Systems von OpenAI ermöglicht es präzise Transkriptionen und vielseitige Einsatzmöglichkeiten, wie die Erstellung von Untertiteln, Übersetzungen und Sprecherkennzeichnungen.
Wie lade ich Audio- oder Videodateien hoch und beginne die Transkription?
Im Datei-Tab können Sie Audio- oder Video-Dateien im unterstützten Format hochladen. Wählen Sie anschließend das gewünschte Modell, die Sprache und das Ausgabeformat aus (SRT, WebVTT, TXT etc.), und klicken Sie auf „Generate Subtitle File“, um Ihre Transkription zu starten.
Im YouTube-Tab können Sie dasselbe tun, aber, anstatt eine Datei hochzuladen, können Sie den YouTube-Link zum Video verwenden.
Im Mikrofon-Tab können Sie den Audioinhalt direkt über Ihr angeschlossenes Mikrofon aufnehmen.
Welche Dateiformate können generiert werden?
Whisper-WebUI unterstützt mehrere Dateiformate für die Ausgabe Ihrer Transkriptionen:
- TXT: Unformatierter Text ohne Zeitmarken, geeignet für reine Transkripte
- SRT: Standardformat für Untertitel in Videos, inklusive Zeitstempel
- WebVTT: Für Untertitel, die speziell für Web-Anwendungen optimiert sind
- LRC: Für Liedtexte
Wählen Sie das gewünschte Format über die Dropdown-Liste im Bereich Ausgabeformat aus. Dies ermöglicht eine flexible Anpassung der Transkription an Ihre spezifischen Anforderungen.
Wie sicher ist der Umgang mit sensiblen Daten?
Whisper-WebUI wird auf universitätseigenen Servern betrieben werden, sodass Ihre Daten ausschließlich intern verarbeitet werden. Dies schützt sensible Inhalte und gewährleistet die Einhaltung der Datenschutzrichtlinien der Goethe Universität.
Es findet nur eine temporäre, kurzfristige Speicherung der hochgeladenen Daten und generierten Transkripte und Zugriff auf diese Daten haben nur die Administrator*innen der Plattform
Bevor Sie sensible Daten an den Dienst weitergeben, informieren Sie sich genau über die Bestimmungen und ggf. vorhandenen rechtlichen Regelungen zum Umgang mit den zu transkribierenden Daten. Stellen Sie sicher, dass eine interne Weiterverarbeitung erlaubt ist, und keine Persönlichkeits-, Urheber- oder andere Rechte verletzt werden.
Wer kann Whisper-WebUI nutzen?
Die Anwendung steht allen Studierenden und Lehrenden der Goethe Universität zur Verfügung. Sie wurde von studiumdigitale konfiguriert und wird auf den universitätseigenen Servern gehostet.
Features
Auswahl des Whisper-Modells – Wie treffe ich die richtige Entscheidung?
Whisper-WebUI ermöglicht die Auswahl von verschiedenen Transkriptionsmodellen (z. B. „tiny“, „base“, „large-v2“). Die Modelle variieren in Geschwindigkeit und Genauigkeit:
- Kleine Modelle (z. B. „tiny“): Schneller, ressourcensparend (ca. 1 GB GPU-RAM) und ideal für einfache Aufgaben.
- Große Modelle (z. B. „large-v2“): Bieten maximale Präzision, benötigen jedoch mehr Ressourcen (bis zu 10 GB GPU-RAM).
Normalerweise, sollte das voreingestellte Modell allen Anforderungen entsprechen, sollte jedoch der Bedarf bestehen, können Sie auch ein anderes Modell ausprobieren.
Stellen Sie sicher, dass Sie die Ausgabequalität des Modells überprüfen. Obwohl größere Modelle normalerweise genauer sind, gilt diese Regel nicht immer.
Wie stellt Whisper-WebUI die Ausgangssprache einer Aufnahme fest?
Standardmäßig ist die automatische Spracherkennung aktiviert und verscucht, die Sprache der Aufnahme automatisch zu identifizieren:
- Sie können die Sprache manuell festlegen (z. B. Deutsch) oder die vorkonfigurierte automatische Sprachdetektion verwenden.
- Die KI analysiert den Inhalt und optimiert die Transkription basierend auf der identifizierten Sprache.
Die automatische Funktion eignet sich für Dateien mit einer einzigen dominanten Sprache und erfordert keine zusätzliche Anpassung.
Kann ich Dateien von anderen Quellen wie YouTube oder live durch Mikrofonaufnahmen transkribieren?
Ja, Whisper-WebUI unterstützt mehrere Eingabemethoden:
- Direktes Hochladen von Dateien:
Im Datei-Tab können Sie Audioclips per Drag-and-Drop oder über den Upload-Button hinzufügen.
- Transkription von YouTube-Videos:
Im YouTube-Tab fügen Sie den Link eines Videos ein. Die Anwendung extrahiert den Audiostream und verarbeitet ihn wie jede hochgeladene Datei.
- Live-Aufnahmen über Mikrofon:
Nutzen Sie den Mikrofon-Tab, um direkt über ein angeschlossenes Mikrofon Audio aufzunehmen und in Echtzeit zu transkribieren.
Diese flexiblen Eingabemöglichkeiten machen Whisper-WebUI sowohl für lokale Dateien als auch für Online-Inhalte geeignet.
Bitte überprüfen Sie das Ergebnis der Sprechererkennung, da die Modelle die Sprecher möglicherweise immer noch verwechseln, insbesondere wenn die Anzahl der Sprecher groß ist oder die Audioqualität nicht sehr gut ist.
Kann ich verschiedene Sprecher*innen automatisch erkennen? (Diarization)
Ja, die Sprecher*innen-Erkennung (Diarisierung) hilft dabei, verschiedene Sprecher*innen in einer Audiodatei zu identifizieren:
- Aktivieren Sie die Option „Sprechererkennung“ im Funktionsbereich.
- Whisper-WebUI analysiert die Datei und teilt diese in Abschnitte, die Sprecher*innen-Tags (z. B. „Speaker 1“, „Speaker 2“) enthalten.
Diese Funktion ist besonders hilfreich für Interviews, Gruppendiskussionen oder Meetings, da sie die Struktur und Lesbarkeit der Transkription verbessert und Klarheit schafft, wer was gesagt hat.
Welche Dateiformate werden unterstützt?
Sie können die folgenden Formate hochladen:
Audio: mp3, wav, wma, aac, flac, ogg, m4a, aiff, alac, opus, ac3, amr, au, mid, midi, mka
Video: mp4, mkv, flv, avi, mov, wmv, webm, m4v, mpeg, mpg, 3gp, f4v, ogv, vob, mts, m2ts, divx, mxf, rm, rmvb, ts
Kann ich große Dateien zur Transkription hochladen?
Um sicherzustellen, dass die hochgeladenen Dateien korrekt hochgeladen und transkribiert werden, ist die Dateigröße auf 400 MB und die Audio-/Videolänge auf 30 Minuten begrenzt. Dies ergibt sich aus den verfügbaren Rechenressourcen. Für größere Dateien empfehlen wir, diese mit dem VLC-Tool in eine Audiodatei (z. B. .mp3) zu konvertieren. Gerne stellen wir Ihnen unter dem folgenden Link eine ausführliche Anleitung zum Herunterladen und Verwenden von VLC zur Verfügung, damit Sie Ihre großen Videodateien in Audio umwandeln können. Diese Audiodateien können dann problemlos mit Whisper-WebUI transkribiert werden.
https://lehre-virtuell.uni-frankfurt.de/vlc-installieren-und-ein-video-in-audio-konvertieren/
Für Dateien, die länger als 30 Minuten sind, empfehlen wir die Verwendung einer Software wie Audacity oder Microsoft ClipChamp, um die Datei in mehrere kürzere Dateien aufzuteilen.
Kann ich Hintergrundmusik oder störende Geräusche herausfiltern?
Die Background Music Removal (BGMR)-Funktion nutzt KI-basierte Modelle, um Sprache von Hintergrundmusik zu trennen:
- Aktivieren Sie die Option „Hintergrundmusik-Entfernungsfilter“ vor der Transkription.
- Die Software verarbeitet die Datei und fokussiert die Transkription auf den Sprachinhalt. Musik und Umgebungsgeräusche werden herausgefiltert.
- Im Expertenmodus können Sie die Parameter des angewendeten AI-Modells anpassen, wie die Segmentgröße oder das spezifische Modell, um die Trennqualität zu optimieren.
Alternativ kann die Funktion im BGM Separation Tab genutzt werden, um separate Audio-Dateien für Instrumentale und Vocals zu exportieren.
Welche Funktionen bietet der Silero Voice Detection Filter (VAD)
Der Voice Activity Detection (VAD)-Filter identifiziert Sprache und filtert Stille oder nicht-sprachliche Geräusche aus der Aufnahme:
- Aktivieren Sie die Option „Silero VAD-Filter“ im Funktionsbereich.
- Whisper-WebUI analysiert die Aufnahme und ignoriert Abschnitte, die keine menschliche Sprache enthalten.
- Für feinere Einstellungen können Sie im Expertenmodus Parameter anpassen, wie:
- Speech Threshold: Legt fest, wie laut ein Segment sein muss, um als Sprache erkannt zu werden.
- Minimum Silence Duration: Bestimmt die Länge der Pausen, die ein Segment als abgeschlossen markieren.
Der VAD-Filter ist ideal für Aufnahmen mit langen ruhigeren Abschnitten oder Hintergrundgeräuschen.
Kann ich Untertitel in andere Sprachen übersetzen?
Ja, über den Text zu Text Übersetzung-Tab können Sie bestehende Untertitel-Dateien (SRT oder WebVTT) hochladen und mit NLLB oder DeepL übersetzen. Für die Übersetzung mit DeepL benötigen Sie einen eigenen DeepL-API-Key
- Laden Sie Ihre Untertitel-Datei hoch.
- Wählen Sie das Übersetzungsmodell und die Ausgangs- sowie Zielsprache.
- Stellen Sie zusätzliche Einstellungen wie „Maximale Zeilenlänge“ oder „Zeitstempel hinzufügen“ ein.
- Starten Sie die Übersetzung durch Klick auf „Translate Subtitle File“.
Das Ergebnis ist eine neue Untertitel-Datei in der gewünschten Zielsprache.
Beachten Sie, dass Sie diese Funktion zum Übersetzen aller Textdateien verwenden können, nicht nur der mit dem Tool erstellten Untertitel.
Was bedeutet die Queue (zum Beispiel „queue: 2/3“)
Das bedeutet, dass mehrere Personen das Tool gleichzeitig nutzen und Ihre Anfrage derzeit in der Queue steht. Im Beispiel „Queue: 2/3“ bedeutet dies, dass Ihre Anfrage die zweite in einer Queue von drei Anfragen ist.
Experten Modus
Wie unterscheidet sich die Standard-Oberfläche vom Expertenmodus?
Whisper-WebUI bietet eine Standard-Oberfläche, die vorkonfigurierte Einstellungen für die wichtigsten Funktionen liefert. Dies ermöglicht eine schnelle und unkomplizierte Nutzung, bei der Features einfach ein- oder ausgeschaltet werden können, wie beispielsweise:
- Sprecher*innen-Erkennung,
- Hintergrundmusik-Entfernung,
- und das Aktivieren von Filtern wie Voice Activity Detection (VAD).
Der Expertenmodus hingegen ist für erfahrene Nutzer*innen konzipiert und bietet erweiterte Optionen zur Feinabstimmung der Transkriptions- und Übersetzungsprozesse. Sobald die Funktion „Expertenmodus aktivieren“ eingeschaltet ist, werden weiterführende Einstellungen und Parameter sichtbar, wie:
- Beam Size: Verbessert die Genauigkeit durch breitere Suchlogik, auf Kosten der Geschwindigkeit.
- Silence/Log-Prob Thresholds: Legt fest, wie sensitiv Whisper auf stille oder leise Abschnitte reagiert.
- Initial Prompt: Ermöglicht die Eingabe eines kontextuellen Hinweises, beispielsweise technischer Begriffe oder spezifischer Namen.
- Temperature/Sampling: Kontrolliert die Zufälligkeit und Diversität der Transkriptionsergebnisse.
Die Wahl zwischen Standard- und Expertenmodus hängt von den Anforderungen und dem Kenntnisstand der Nutzer*innen ab. Für viele Anwendungsfälle reicht die Standard-Oberfläche aus, während der Expertenmodus tiefere Anpassungen ermöglicht.
Detaillierte Tutorials und eine Beschreibung aller erweiterten Parameter (wie Beam Size, Silence Thresholds oder Initial Prompts) finden Sie direkt in der Anwendung oder auf der offiziellen Dokumentationsseite: Whisper-WebUI Wiki.
Wo finde ich detaillierte Anleitungen und erweiterte Einstellungen?
Detaillierte Tutorials und eine Beschreibung aller erweiterten Parameter (wie Beam Size, Silence Thresholds oder Initial Prompts) finden Sie direkt in der Anwendung oder auf der offiziellen Dokumentationsseite: Whisper-WebUI Wiki.